(회사 소스를 제거하다보니, 너무 난해한 문서가 되었음. 관련 내용은 한번더 예제 샘플 생성 후, velog 쪽으로 신규 개설 후 작성해야할듯..)
관련 용어 정리
객체 폭발
- 계층간 사용되는 데이터 구조를 다른 계층에서 사용 시 또다시 객체를 만들 때 중복되서 다시 객체가 생성되는 현상을 의미함.
응집도
- 하나의 클래스가 하나의 기능(책임)을 순도 높게 담당 (해당 문서에서는 기능적 응집에 국한되어 이야기함.)
Entity, Domain : 엔티티 정의 (데이터베이스의 필드[컬럼])
- 핵심 업무 규칙을 캡슐화
- 메서드를 가지는 객체 거나 일련의 데이터 구조와 함수의 집합
- 가장 변하지 않고, 외부로부터 영향받지 않는 영역
UseCase
- Service (UseCase) : 비즈니스 규칙 정의 (Service → ServiceImpl)
- ServiceImpl : 비즈니스 구체화
- 애플리케이션에 특화된 업무 규칙을 포함
- 시스템의 모든 유스 케이스를 캡슐화하고 구현
- 엔티티로 들어오고 나가는 데이터 흐름을 조정하고 조작
전통적인 Controller, Service, Repository
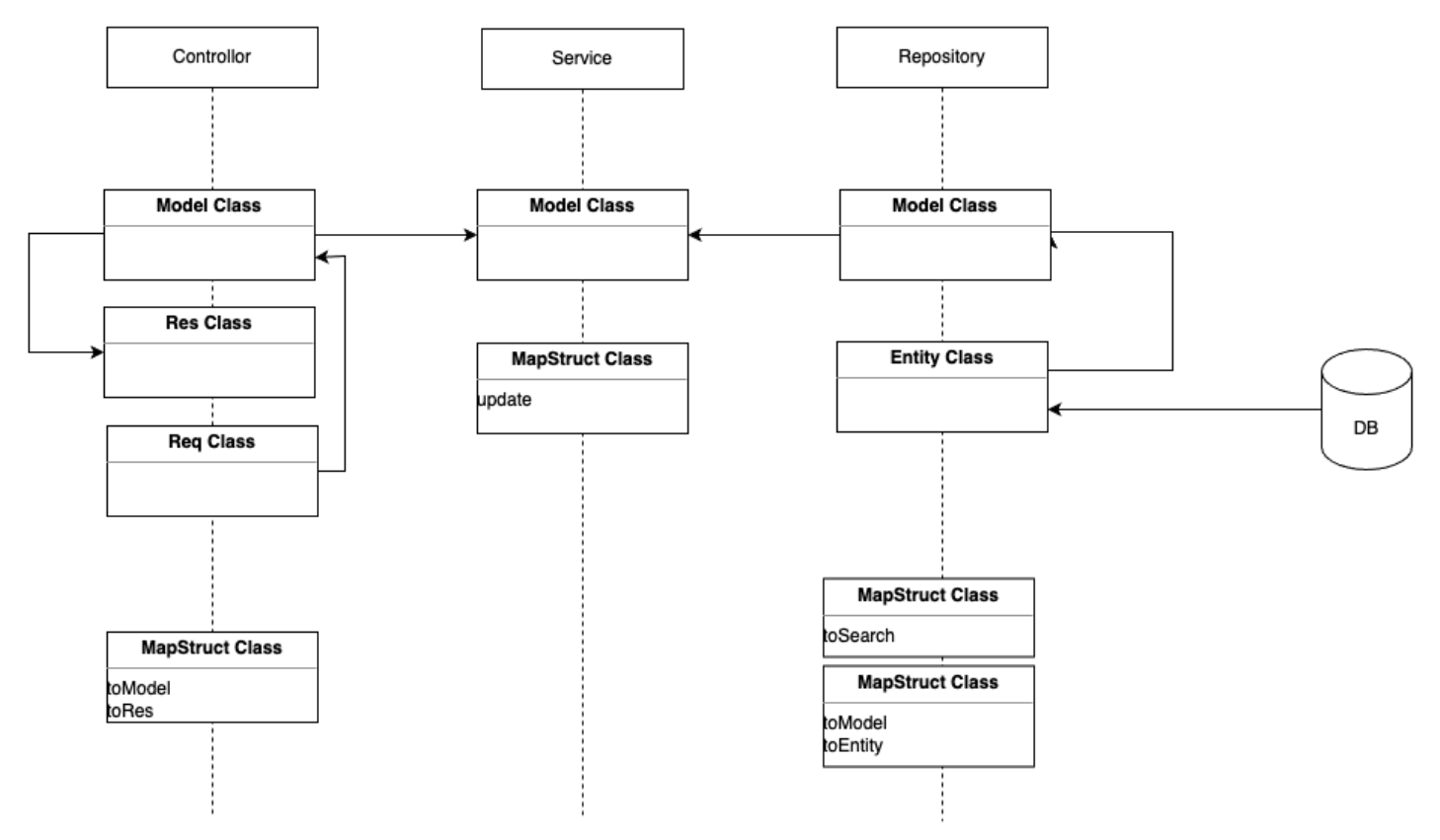
mapstruct 를 이용한, 전통적인 웹 애플리케이션 구조입니다.
웹 계층, 도메인 계층, 영속성 계층으로 구성되어있습니다.
웹 계층은 도메인 계층에 의존하고,
도메인 계층은 영속성 계층에 의존하기 때문에 자연스레 데이터베이스에 의존하게 됩니다.
전통적인 계층형 아키텍처에서 전체적으로 적용되는 유일한 규칙은,
특정한 계층에서는 같은 계층에 있는 컴포넌트나 아래이 있는 계층에만 접근 가능하다는 것이다.
따라서 상위 계층에 위치한 컴포넌트에 접근해야한다면, 해당 컴포넌트를 계층 아래로 내려버리면 됩니다.
그리고 그런 내려지는 행위가 반복되면, 지름길을 만드는 것을 당연하게 생각하면,
하위 계층은 점점 비대하게 됩니다.
계층(Layer)를 구분하는 이유는 다음과 같습니다. 프로젝트의 이해도가 낮아도 전체적인 구조를 빠르게 이해가능합니다. (메소드명의 목적이 명확할 수록 더욱 빠르게 이해가능합니다.) 작성하고자하는 계층이 명확할 수록 더 빠르게 개발가능합니다.
다만, 각 레이어별로 수집개의 클래스들이 존재하게 되면서 코드 파악이 더욱 어려워질 수도 있으며, Layer 기준으로 분리했기에 코드의 응집도가 떨어질 수 있습니다.
그래서 1차 개발 시, 그 계층을 중지시키기 위한 Reader, Writer 를 만들었습니다.
추후, Master, Slave 의 구성을 위해서 분리하는 작업을 진행했습니다.
Request 객체를 전달하게 되면 의존성이 생기므로 전송 데이터 객체(DTO)와 같은 형태로 Wrapping하여 전달.
Return type의 경우 최종 응답 데이터 뿐만 아니라 다양한 정보(Meta data)들을 담아야 하는 상황이 발생할 수 있으므로 애그리거트 객체를 생성하여 사용
이 두가지를 편하게 사용하기 위해 mapstruct 를 도입하게 되었습니다. (https://mapstruct.org/)
그외의 규칙
- 파라미터는 단 한개만 사용 (강제 사항은 아님)
- 모든 프론트엔드의 return 하는 데이터는 테이블 기반으로 합니다. (필드명 등 편의성 사용)
- 중복은 허용되지 못합니다. 우발적 중복은 허용가능합니다.
진짜 중복 - 한 인스턴스가 변경되면, 동일한 변경을 그 인스턴스의 모든 복사본에 반드시 적용해야한다. 우발적 중복(거짓된 중복) - 중복으로 보이는 두 코드의 영역이 각자의 경로로 발전한다면, 즉 서로 다른 속도와 다른 이유로 변경된다면 이 두 코드는 진짜 중복이 아니다.
와 같은 다양한 규칙으로 만들어진 계층 구조는 다음과 같습니다.
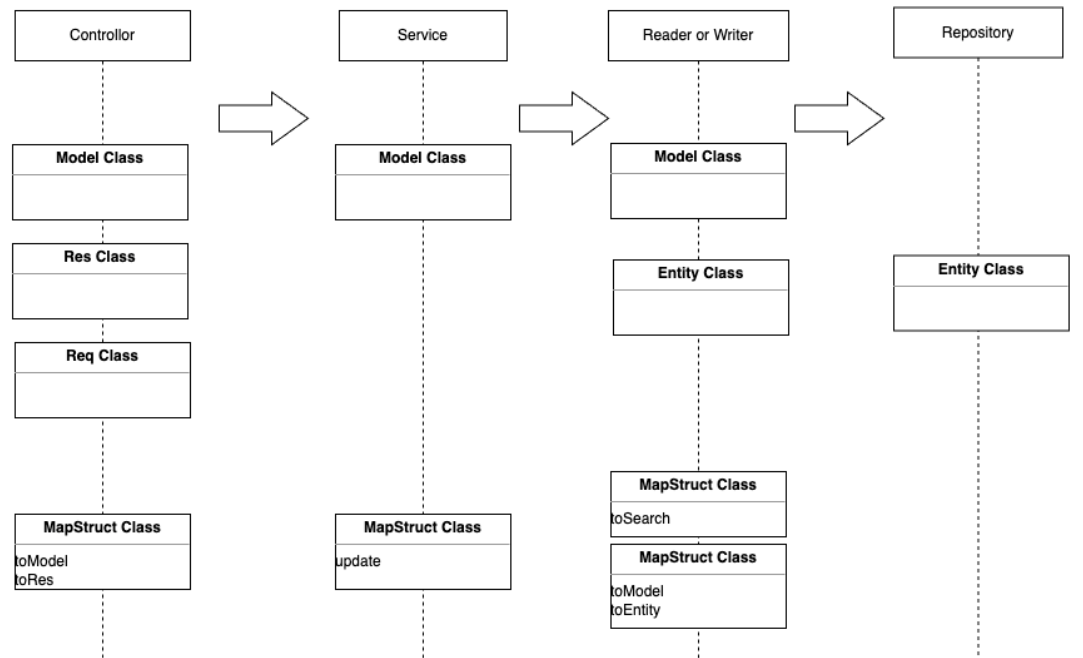
컨트롤러 → Service → Reader(or Writer) → Repository 형태로 호출됩니다. Service는 Use Cases 영역에 속하며, 각 계층간 분리를 위해, 서비스 영역은 Model 객체만 가지며, 컨트롤러와 Reader에서 Entity , Payload 등의 데이터를 Model 객체로 가공하여 전달합니다. (이때 MapStruct 가 사용됩니다.)
Reader와 Writer를 도입한 이유는 persistence 영역의 JDBC 가 JPA로 변경되었을 때나, DB 이중화 작업 시,
Service(Use Cases)의 최소한의 변경을 위하여 도입하였으나,
결국 불필요한 복제가 필요한 로직이 되었습니다.
불필요한 Reader 와 Writer 를 지우고 경량화가 가능하자는 의견들이 나오게 되었습니다.
그리고 Service 또한 모듈로 분리하는 것입니다.
추후 Master, Slave 시 Replication 대응을 위해 필요할 수도 있지만, 어노테이션으로 슬레이브, 마스터를 가리킬 수 있으므로 큰 강제성을 하지 않아도 된다고 생각합니다.
신규입사자분의 경우 대부분의 기존 Controller, Service, Repogitory 환경에서 작업했을 테니,
이해하거나 적응하기 어렵고, 우회할 수 있는 여러 여지가 있기 때문에, 강제성을 가지고 개발을 할 수 있는 구조가 무엇인지 다시금 고민하게 되었습니다.
(ex : 주입이 상관없으므로 interface 없는 @Service 생성, Service에서 바로 Repogitory 호출을 막을 방법이 없는 등.)
격리벽을 높여 강제성을 만드는 여러 방법 중에는 public > protected > default > private 에 default 만 정의하여 ,
구현체는 스프링부트의 어노테이션에서 주입하는 형태로만 허용 등이 있을 수 있었습니다.
결국 클린 아키텍쳐로 구성된 최종 서비스 구성도 입니다.
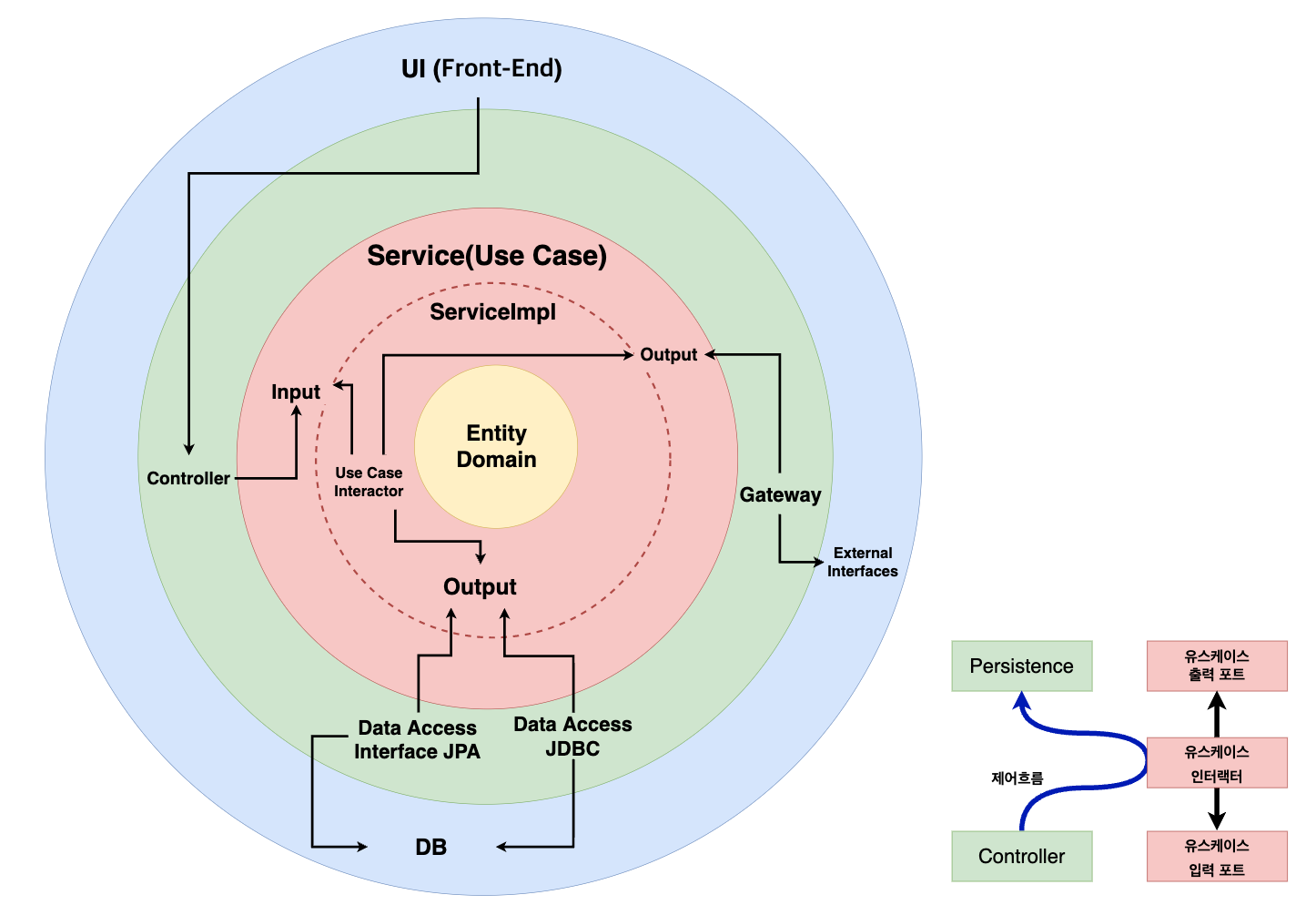
input 과 output 으로 만들어진 구조를 간단하게 포트 & 어댑터 디자인 패턴이 적용된 모듈입니다.
잘못된 의존성을 막기 위해 아키텍쳐를 여러 개의 빌드 아티택트로 만드는 여러가지 방법을 “만들면서 배우는 클린 아키텍쳐”란 책에서 영감을 받았습니다.
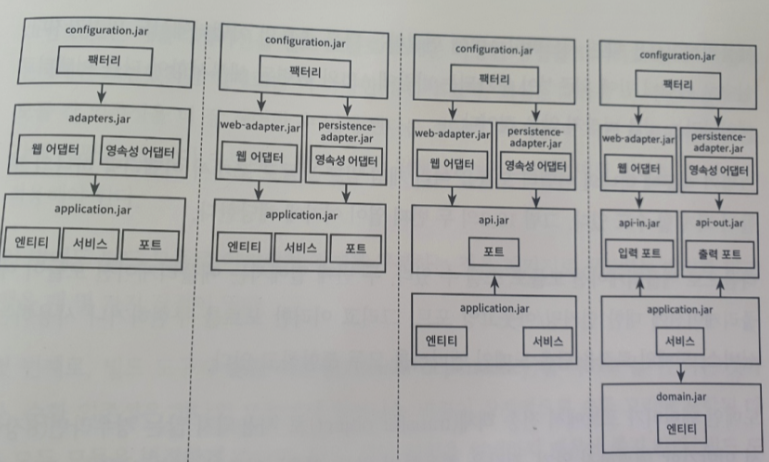
해당 구조에서 왼쪽에서 2번째 항목으로 구성을 구현하게 되었습니다.
어댑터 패턴 (adapter pattern)
한 클래스의 인터페이스를 클라이언트에서 사용하고자하는 다른 인터페이스로 변환합니다.
어댑터를 이용하면 인터페이스 호환성 문제 때문에 같이 쓸 수 없는 클래스들을 연결해서 사용할 수 있으며, 호환되지 않는 인터페이스를 사용하는 클라이언트를 그대로 활용할수도 있습니다.
이렇게 함으로써 클라이언트와 구현된 인터페이스를 분리시킬수 있으며, 향후 인터페이스가 바뀌더라도 그 변경 내역은 어댑터에 캡슐화 되기 때문에 클라이언트를 바꿀 필요가 없어집니다.
여기서 Port 개념이 추가되면서, 보통 포트와 어댑터 패턴이라고 합니다.
이미 api-admin 란 서비스를 구현한다고 했다면, 실제 구조는 다음과 같습니다.
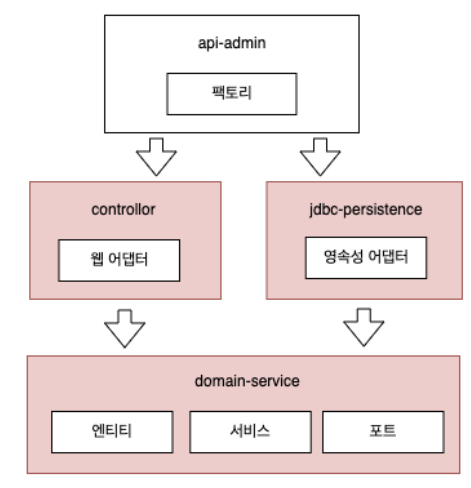
컨트롤러 영역인 presenters 모듈
서비스 영역인 usecases 모듈
그리고 jdbc 를 직접구현하거나 이미 만들어져있는 Repogitory 모듈을 dependence하는 persistence 모듈로 분리합니다.
presenters-xxxx
dependencies
dependencies {
implementation(project(":modules:common-util"))
implementation(project(":modules:common-payload"))
implementation(project(":modules:modules-usecases:usecases-xxxx"))
// mapstruct
implementation("org.mapstruct:mapstruct:1.4.2.Final")
annotationProcessor("org.mapstruct:mapstruct-processor:1.4.2.Final")
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-validation'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.7.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.7.0'
}
공통 payload
공통 utils
usecases
mapstruct
springboot-web
- package 구조
동일 class 는 구현체 오류가 나는 걸 방지하기 위해 앞에 Presentation 의 약어 Pre를 붙여서 만듬.
persistence-xxxx
dependencies
dependencies {
implementation(project(":modules:repository"))
compile(project(":modules:db"))
implementation(project(":modules:common-util"))
implementation(project(":modules:modules-usecases:usecases-xxxxx"))
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
runtimeOnly 'org.mariadb.jdbc:mariadb-java-client'
implementation 'org.springframework.boot:spring-boot-starter-web'
// mapstruct
implementation("org.mapstruct:mapstruct:1.4.2.Final")
annotationProcessor("org.mapstruct:mapstruct-processor:1.4.2.Final")
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.7.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.7.0'
}
modules:repository
modules:db
modules:common-util
modules:modules-usecases:usecases-xxxxx
- 패키지 구조
usecases-xxxx
dependencies
dependencies {
implementation(project(":modules:common-util"))
implementation(project(":modules:message"))
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.7.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.7.0'
// https://mvnrepository.com/artifact/org.mariuszgromada.math/MathParser.org-mXparser
implementation group: 'org.mariuszgromada.math', name: 'MathParser.org-mXparser', version: '4.4.2'
implementation 'org.springframework.boot:spring-boot-starter-web'
}
- 패키지
port.input →
port.output →
트랜젝션 위치?
@Transactional
implementation("org.springframework:spring-tx:5.3.6")
원하는 위치나 로직이 있을 경우 dependencies 에 추가함.
에 추가함.
모든 맵핑을 처리할 것인가?
디코드 3.0의 경우 객체 폭발이라고 할 정도로, entity → model → payload(request,response) 형태의 객체를 만들었습니다.
-
- 완전 맵핑 전략으로 갈 것인가?
- 결합을 낮추는 게 안정적이라는 기준을 가진다면, 완전 맵핑이 맞습니다.
- entity 의 필드 변경이 request, response에 영향을 주면 안된다.
- 격리벽 → entity
-
- 불완전 맵핑 전략으로 갈 것인가?
- 단순 CRUD 인 api-admin 에서는 비즈니스 모델의 변경이 entity, payload에까지 영향을 주었습니다.
- trade-off 에 맞추어 각자 생각하여 진행할 것인가? : 개발자 본인의 판단의 선택을 존중합니다. 도메인의 복잡도가 높을 수록, 도메인모델(Entity)를 전체 노출 시킬일이 거의 없을 겁니다. 그러나 복잡도가 낮을 경우에는 도메인모듈에 곧 테이블(DB)며, request Json 이 되므로, 객체폭발을 시킬 이유가 없다고 보여집니다.