CLUSTER NODES
lod 현재 상황은 cluster nodes 라는 명령어를 통해 보일 수 있습니다.
CLUSTER NODES는 클러스터에 참여하고 있는 노드의 정보를 보는 명령으로,
접속한 서버가 가지고 있는 클러스터에 속한 다른 노들의 정보입니다.
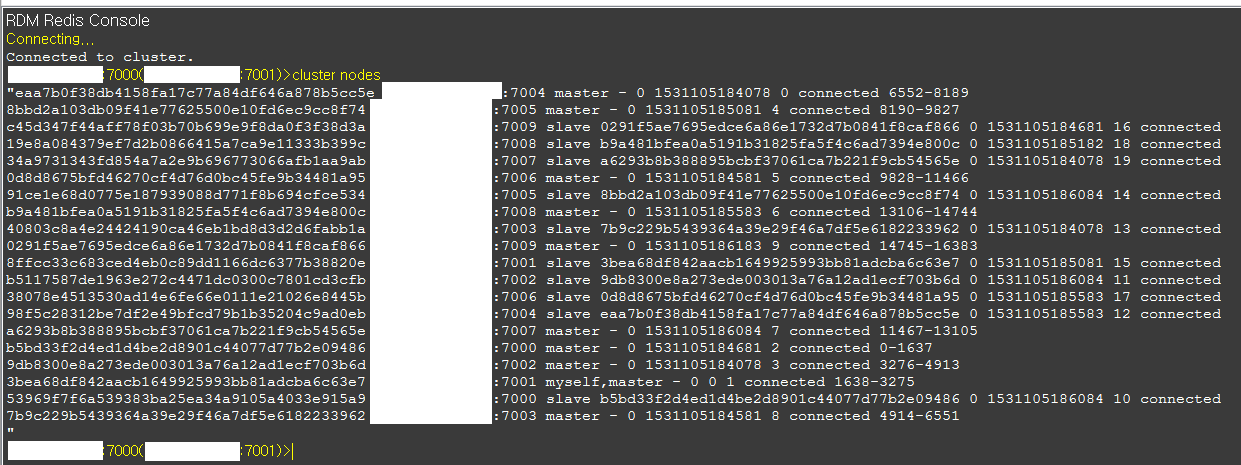
- node-id : 노드를 유일하게 구분할 수 있는 ID며, 40개 문자로 구성되면 변경되지 않습니다.
- ip:port : 노드의 주소로 IP와 Port 입니다.
- flags : master, slave, fail?, fail, handshake, noaddr, noflags가 있고, 명령을 실행한 노드에 myself 라고 표시된다고 합니다.
- master : 슬레이브일 때 마스터 노드 ID가 표시되며, 마스터일 때는 “-“이 표시됩니다.
- ping-sent : myself가 다른 노드에 ping을 보낸 시각(Unix timestamp milliseconds)입니다.
주의할 것은 7000번이 7001번에게 Ping을 보냈으면 ping-sent가 7000번에 기록되는 것이 아니고 7001번에 기록된다고 합니다.
Ping-sent 시각은 Pong이 오면 지워지므로 이 시각은 아직 Pong 오지 않았을 아주 짧은 시간만 볼 수 있다고 합니다.
따라서 대부분의 경우 0으로 나온며, Myself는 이 값이 항상 0입니다. - pong-recv : Pong을 받은 마지막 시각(Unix timestamp milliseconds)을 의미합니다.
7000번이 7001번으로부터 Pong을 받으면 7000번이 가지고 있는 7001번 데이터에 기록되며, Myself는 이 값이 항상 0입니다. - config-epoch : The configuration epoch (or version) of the current node (or of the current master if the node is a slave). Each time there is a failover, a new, unique, monotonically increasing configuration epoch is created. If multiple nodes claim to serve the same hash slots, the one with higher configuration epoch wins.
- link-state : 클러스터 버스로 연결된 상태를 나타냅니다.
connected 또는 disconnected 라고 합니다. - slot : 마지막 항목은 할당된 슬롯 정보입니다.
슬롯이 할당된 마스터 노드에 범위로 표시됩니다.
슬레이브나 슬롯이 할당되지 않은 마스터는 표시되지 않습니다.
Redis CLUSTER nodes.conf 파일
서버에서 [CLUSTERDOWN The cluster is down] Error 가 발생하기 시작했습니다.
[ERROR][2018/06/28 16:04:31] c.m.d.r.RedisExecutor$RedisCommonPattern [86]
###### ERROR LOG ######
CLASS_NAME : Protocol.java / LINE : 115 / MESSAGE : redis.clients.jedis.exceptions.JedisClusterException: CLUSTERDOWN The cluster is down
CLASS_NAME : Protocol.java / LINE : 151 / MESSAGE : redis.clients.jedis.exceptions.JedisClusterException: CLUSTERDOWN The cluster is down
###### END ERROR LOG ######
SCOUTER 에서 사용하고 있는 ip 와는 다른 클러스터 ip 가 보이며, time out이 발생하는 현상이었습니다.
어플리케이션에서는 해당 IP를 호출하는 부분이 적혀 없었기에,
위의 서술한 cluster nodes 를 검색해보니, SCOUTER 에 찍혔던 ip 와 같은 클러스터 ip가 찍히는 것을 확인할 수 있었습니다.
원인은 별도의 검증계 서버를 구축하기 위해 레디스를 구축하던 과정에서, 뭔가 grouping 이 가능한 동일 id를 설정하면서, 해당 ip 까지 동일한 클러스터로 판단하여, 클러스터링된것으로 보이며,
급한 이슈 해결을 해야하므로, 레디스를 다시 밀어버리고, 재설치하는 방법으로 해결되었습니다. (이게 해결일 수는 없습니다.)